Article
What are Data Structures? A Guide for Beginners
![]()
Written By Imogen Crispe
Last updated April 4, 2019
![]()
Written By Imogen Crispe
Course Report strives to create the most trust-worthy content about coding bootcamps. Read more about Course Report’s Editorial Policy and How We Make Money.
Course Report strives to create the most trust-worthy content about coding bootcamps. Read more about Course Report’s Editorial Policy and How We Make Money.
As an aspiring software engineer, you need to learn programming languages like JavaScript, Ruby, or Python. But what else can you learn to stand out from the crowd and land a job? That’s where computer science fundamentals like data structures come in. Fred Zirdung, who has taught data structures at Hack Reactor since 2012 and is now Head of Curriculum, explains what data structures are, how various websites use them, and where beginners should start when learning data structures.
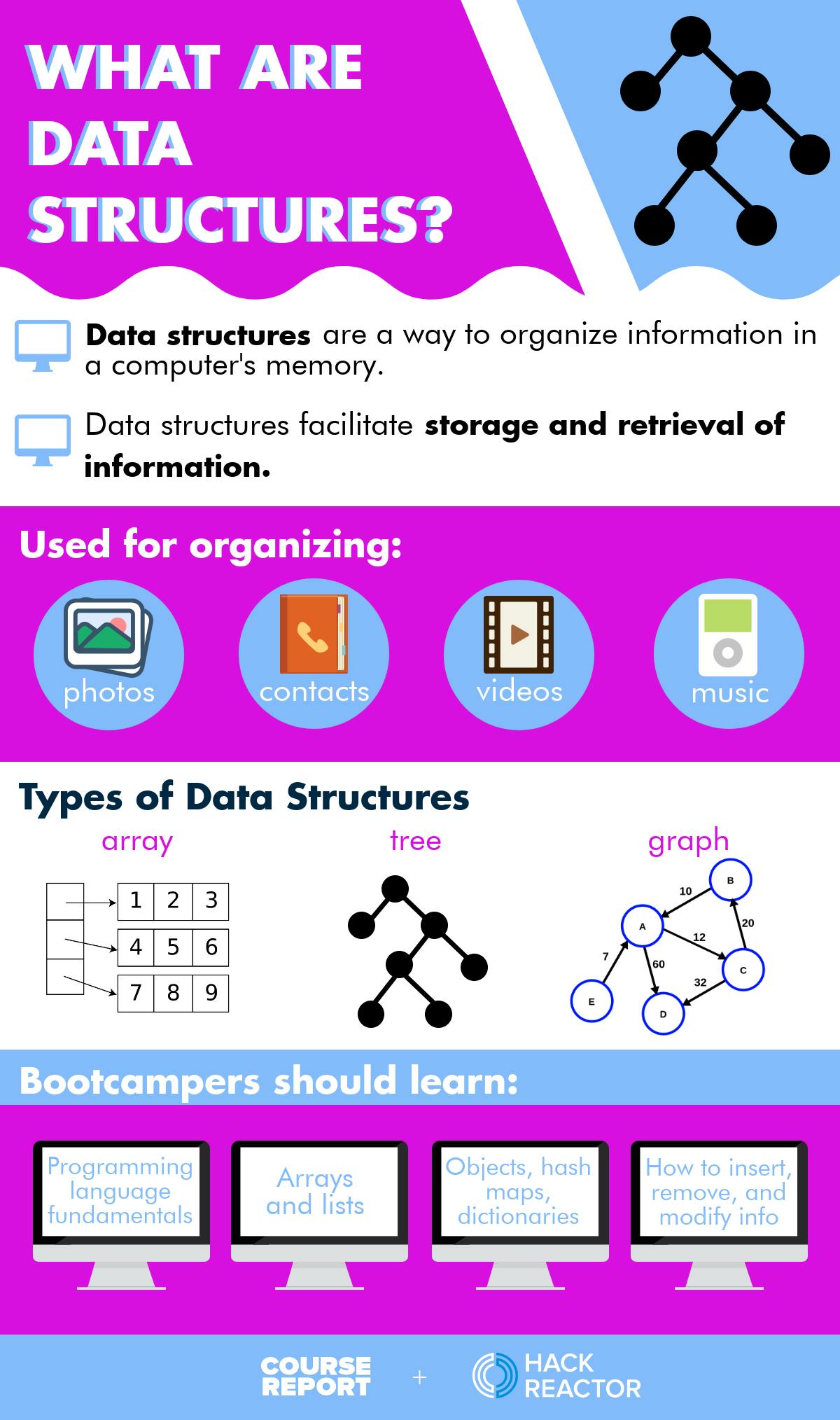
Data structures are a way to organize information in a computer's memory.
To understand the why behind them, I'm going to use a real-life analogy to get us to the point of being able to talk about it with computers.
If you think about what is happening there, it's all about storage and retrieval of information. When you look up a book in a card catalog, signs in the library tell you where that number is located and then you look for the shelf that you would find that number on.
That's what computers are doing with large amounts of information. It's not useful to use computers to solve problems of storing six books, but it is useful to use computers to look up millions of books.
Finding the information associated with what you want to examine is an important process of everyday life. And with the internet, we rely on this for everything, including:
Arrays
Arrays are very common and one of the most fundamental data structures. Arrays are really just a list of items (eg. a list of book titles, a list of grades, or a list of scores).
Example: You need a list of alphabetical users for a particular website so that you can look them up by name. The way you find things in an array is by its positional identifier (eg. position K is index 10). That's one of the basic ones.
Object
Another one that's really common for beginners to master is an object. It's essentially an association between two different pieces of information. Usually, one is called a key and it’s associated with a value. Some languages call it an associative array, or a dictionary, or a hash map.
Example: If you've ever filled out a form online, like creating an account, you enter your first name, last name, email, birthday. That's an example of an object. Each field has a title – like first name and last name – with a corresponding value. You can round up those values together, and then you have a representation of what the user filled out.
Tree
A third useful one is a tree. In particular, there's a specific type of tree that's used very widely called a binary search tree. It's binary because it can have a maximum of two ‘children.’ You can think of a tree as an ancestry tree. You can work backwards and create a tree of your parents, grandparents, and great grandparents. The same idea works with information. You can create categorization that gets more and more specific through the same hierarchy. This is useful for finding information by its value.
Example: You want to find the name of a restaurant. That poses a problem for computers because, like a human, if I gave you a randomly sorted phone book, and say, "Find a person in that phone book," it would take you all day. Like a sorted phone book, binary search trees enable us to find information in considerably less time. Instead of having to scan each entry, we can just do it in a small number of steps. As an example of that, if you had a directory that contained 4.3 billion entries in it, it would take only 32 steps to find any entry in that book.
These days, graph data structures are becoming popular because they represent information that can't be represented hierarchically, such as in a tree form. Graph data structures are arbitrary relationships that don't have a parent-child ancestry relationship with each other.
Example: Sometimes on LinkedIn when you try to connect with somebody, it immediately lets you connect with them, and other times, you have to supply the email address of a user. Graph databases figure out what your connectedness is to that user and then prompt you for more information or not. So if you have no connection to a user, and you're trying to befriend them, LinkedIn might put up a blocker. But if you're already interconnected with various people that they know, the graph would indicate that you have connections in common. So adding yet another connection feels like a safe maneuver on their part, and protects users from spammers.
There usually isn't one data structure that is perfect for a given task. There are often multiple possibilities. Sometimes it's an obvious choice, but other times, it's not so obvious and really just boils down to how is the software going to be used.
Problem: You're trying to figure out how to store restaurant information on Yelp.
Thought Process: Every day, millions of users use Yelp to look for restaurants by name. If you think about the usage pattern, probably 99% of users come to Yelp to find a restaurant, and somewhere less than 1% come to Yelp to set up a new restaurant. So a very, very small amount of traffic in the setup case.
Solution: Given that the predominant use case is to search (vs Add a new Restaurant), you would probably pick a data structure that was optimized for looking up by value as opposed to inserting them into the dataset.
Anyone who wants to become a professional engineer needs to understand at least the most common data structures that exist. If you really want to excel at being a software engineer, you should have a good idea of how data structures work internally.
You're almost never going to be asked to build a data structure from scratch in a real production system. You may contribute to it by making it better or fixing a bug, but knowing how they work in on the inside is going to really help you select the right data structure.
What makes you a productive engineer is not necessarily memorizing everything, but being able to make intuitive leaps. Intuitive leaps get you to an answer more quickly than by research alone. And you can narrow down some options by making intuitive leaps based on what you already know and then spending the remaining time doing research on those specific things. This is how you boost your productivity as a software engineer.
I think a good product manager would also need to know what complexities are involved with information management, not necessarily the inner workings of a data structure. But when it comes to information management and retrieval, I think anybody who deals with computers could benefit from understanding some basics about data structures.
In a job interview, you should know not only which data structure to use, but also understand how they work. Companies that value a strong engineering mindset will emphasize knowledge of data structures. So you might be asked to design a data structure from scratch or improve an existing one.
Other companies might ask you how to use data structures, which one you would use, and why but not necessarily to build one from scratch. It really just depends on the company that you're aiming to work for.
Every programming language has data structures built into it. It's fundamental to the task of programming. So regardless of which programming language you pick up, you will interact with data structures pretty quickly in that language. So common ones are:
If you are trying to get a job as a software engineer and you know your data structures well, that might put you at a competitive advantage to a graduate from a bootcamp that doesn't teach data structures. It's just that someone who understands them definitely has a competitive advantage over someone who does not.
Arrays and objects are covered in the prep portion at Hack Reactor. You're expected to know those by the time you arrive at the immersive portion of the program. We spend the first couple weeks of the Hack Reactor curriculum working on CS fundamentals like algorithms, data structures, instantiation patterns, language features, things like that.
We cover nine data structures in total:
An absolute beginner needs to get familiar with the language and the most fundamental data structures that exist in the language, which are:
Arrays and lists
Objects, hash maps and dictionaries.
Be solid on those two data structures – learn how to insert, remove, update, and modify the information. That's going to set you up for all other data structures. If you can't master the basics on those then you're going to struggle in all the rest of them.
Websites like Code Signal, or any problem-centric websites are really great at helping you bolster your skills beyond the basics. The problems may not be data structure specific, but incorporate some sort of algorithm that uses a data structure in the process.
We don't use data structures purely for the sake of using them, for storing information. We're trying to solve problems. So an algorithm that makes use of the appropriate data structure to solve a problem is really exemplary of what you're doing in a large scale system like Yelp or LinkedIn. It's really important to have your fundamentals solid.
Find out more and read Hack Reactor reviews on Course Report. Check out the Hack Reactor website.

Imogen Crispe, Content Creator and Entrepreneur
Imogen is a writer and content producer who loves exploring technology and education in her work. Her strong background in journalism, writing for newspapers and news websites, makes her a contributor with professionalism and integrity.










Enter your email to join our newsletter community.